Lesson 1: Intro to Deep Learning
Learning Goal
This lesson is designed to give you a general overview of the topics that will be applied in this project so that you can then leverage online resources to learn more and also to prepare you in understanding how to upcoming project actually works. At the end of this lesson, you will have a very good understanding of the concepts that will be applied in this guided project and will even be able to do your own Machine Learning projects regardless if you continue with this one. You will understand the basics of Human Intelligence and Learning, Artificial Intelligence Machine Learning, Deep Learning, and Neural Networks.
Pre-Reading
Inro to Deep Learning: https://www.geeksforgeeks.org/introduction-deep-learning/
How Neural Networks work: https://www.youtube.com/watch?v=bfmFfD2RIcg
Intro to Machine learning: https://www.youtube.com/watch?v=KNAWp2S3w94
Deep Learning
Why Deep Learning?
Before we begin learning about Deep Learning and applying it to the project, we must first understand why we should be learning about it in the first place. For the last decade or so, Deep Learning (DL) and Artificial Intelligence (AI) has been at the top of the list in peoples minds when it comes to anyone says the word “technology”. These two terms AI and DL have become synonymous in people’s minds because they have become so widely used. However Deep Learning is the cutting edge in a field that seeks to redefine what intelligence means in humans and computers and apply it to problems for the improvement of society as a whole. Deep Learning has delivered super-human accuracy for image classification, image processing, and language processing. We have been able to use Deep Learning to solve and automate tasks that could never have humans and other machine learning models could never have done on their own. It has allowed us to look at intelligence in a different way and brought us one step closer to understanding what it is the defines intelligence. In the application of Machine Learning (ML) and DL, you will be able to implement and solve problems that you any have never thought achievable and gain a more in-depth understanding of yourself and how you also learn. Deep Learning is just the latest attempt to understand how we work and learn new things. With that, let’s dive into what DL is and a general overview of important topics in ML.
What are the 2 aspects of Machine Learning?
It is important to understand a general perspective of what makes up learning before diving into the topics of Artificial Intelligence, Machine Learning, and Deep Learning. Learning can be viewed to fall into a simple mathematical model:
Learning = Knowledge + Data
It is impossible to learn without some prior knowledge and assumptions on the subject. Assumptions must be made and applied in order for learning to take place. These assumptions are taken from prior knowledge one has. With this prior knowledge and the assumptions made from it we can then begin to learn from the data we have available and begin the process of trial and error that is at the core of all new learning. The process can be simplified to we have an idea of what should happen and what to look for, then we iterate through trails and learn from mistakes until we achieve the desired end result. This is what all ML and DL models do to learn as it at the heart of every single learning process. The more data we have on a particular problem the less prior knowledge we need and the more knowledge we have the less data we need to sole the problem.
Knowledge in the specific application of Machine Learning is utilized through defined features, defined kernels, defining the neural network architecture, etc.
What is the general workflow in building a workable model?
Here we will discuss the general workflow of a machine learning project to give you an idea of how to build one. The general overview of the workflow is show in this diagram:
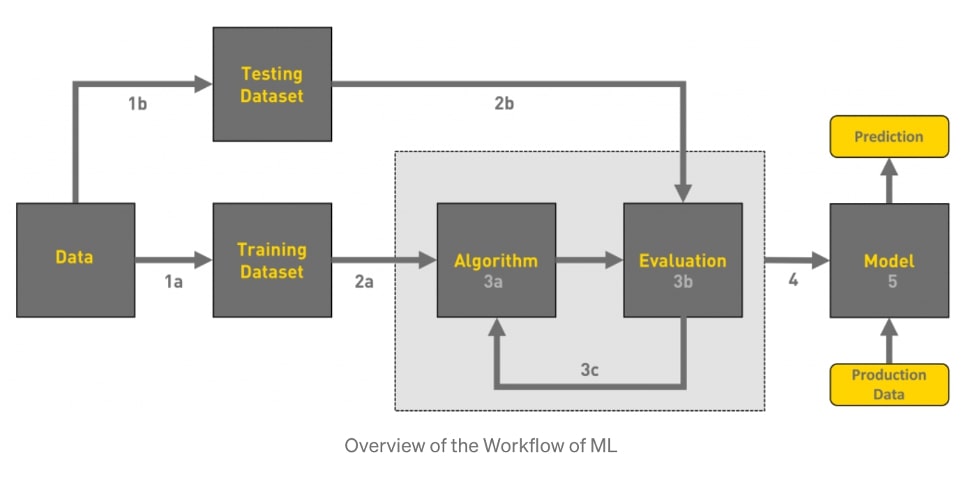
The general workflow follows these 5 steps:
- Gathering data
- Data pre-processing
- Researching the best model for the project
- Training and testing the model
- Evaluation
A ML model is nothing more than a piece of code that someone makes smart through training with data. Here we will go in depth into the workflow process:
1. Gathering Data
This is the part of the process where we gather the data for the machine learning model to be trained and validated on. The data can be collected from files, sensors and many other sources. We can also use free data sources of standardized databases as done in this project. This is where the data has already been collected and compiled into a database for public use to establish a standard for ML models to be trained on and performance measured.
2. Data Pre-Processing
There is an 80/20 rule in ML which states that a person should spend 80% of their time pre-processing the data and the rest training the actual model and performing analysis. This is because data preprocessing is so important when it comes to the accuracy of the model and making sure only the most important data is used to train the model. Data pre-processing is converting the real-world data collected into a clean data set using only the most important features for use in training and validating the model. We need to do this because there could be missing data, noisy data, and inconsistent data in our real world setting that needs to be adjusted for to get an accurate model. This will be handed to you in the form of code in this project in order to save time and keep things on the topic of Deep Learning. In this project the data pre-processing takes place in the form of image conversion and construction as only the image pixel values are handed to us from the public data base used.
3. Choosing Best Model to Train On
The goal of the project is to train the best performing model possible using pre-processed data. There are many different ML algorithms used for different purposes. For example, support vector machines used in classification. The goal is to define what you want to do with this data and choose the best model that does this. In this project, the Deep Learning model we used is called CNN and are discussed in depth later. Here is an overview of the different ML models:
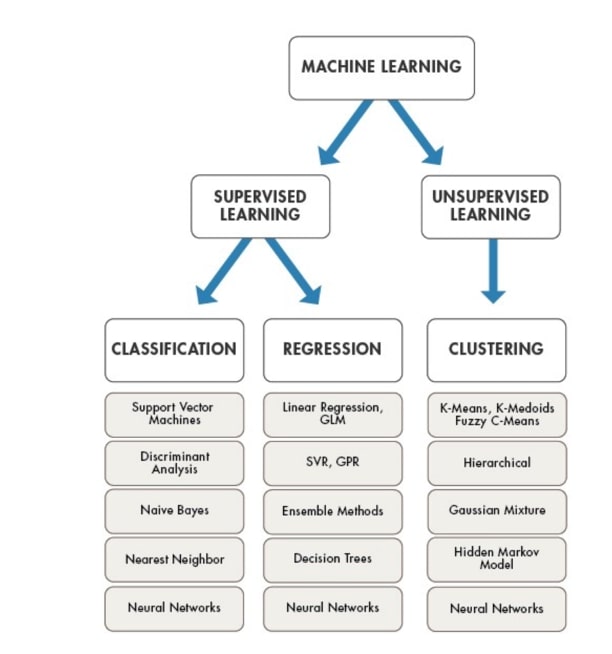
4.Training and Testing Model
For Training a model we split the data into training data, validation data, and testing data. You train the model using the training data, adjust the parameters using the validation data, and test its performance on the testing data.
5.Evaluation
Now that the model is trained and tested, we now apply it in field in the real world and see how it does with real world data. This is done in the project by accessing the build in webcam of the computer and taking real-time frames from the video footage that are fed into the trained CNN model and an output is received.
What is over and under fitting?
Now that we have discussed what defines learning, there is one other important aspect to ML, Data Fitting. The goal of any ML model is to generalize features of the data in order to be able to predict a probable outcome. This is measured in NN’s through the calculation of the cost function and adjustment of the parameters as discussed later. There is a sweet spot in the performance of any ML model where it is able to generalize patterns from the training data to predict a probable outcome while not following the training data exactly. If it follows the training data exactly then the prediction become too specific to the training data and it is not able to take into account any variation of new input data, this is known as overfitting. If it generalizes too much, then the variation the ML model takes into account actually reduces the accuracy of the model, this is known as underfitting. There are 2 important things to understand when it comes to overfitting and underfitting, Bias and Variance. Bias is the assumptions made by the model to make the learning easier, such as defined features. Variance is when you train on the training data and experience very low error, any change is the data fed to this model will result in very high error. Underfitting is High Bias and Low Variance, meaning it cannot capture the underlying trend of the data. Overfitting is Low Bias and High Variance, meaning it follows the training data exactly. A visual example is shown below:
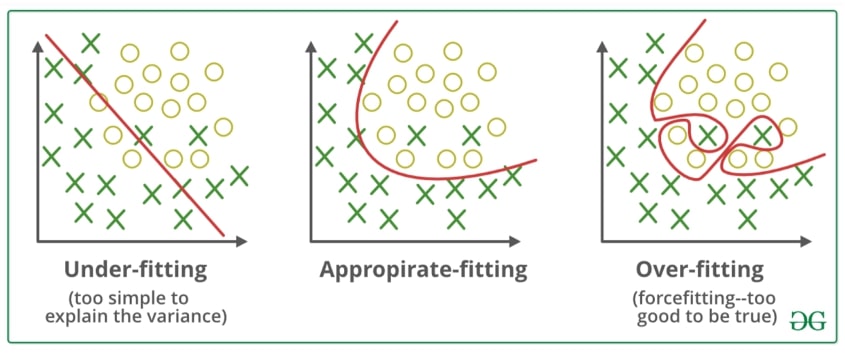
The goal of any ML program is to balance the bias and variance of the output to appropriately follow the trend of the input data.
What is Deep Learning?
Before we begin to answer this question, we must first understand what the whole area of Artificial Intelligence (AI) is as this is the broadest area we can define Deep Learning (DL) to fall under. AI can be simply put as any technique that enables computers to mimic human behavior. We can then narrow this topic even further to Machine Learning (ML). Machine Learning is the for computers to Learn without being explicitly programmed. I am not going to go into the techniques used in this field as that would be a whole other lecture series all by itself and we are focused on the application of deep learning specifically in this project. Now that we have broad understanding of the most general layers that define DL, we can begin to understand what DL is specifically. DL is the extraction of patterns from data using neural networks.
To illustrate the difference between these areas let us take a look at some examples. An example of AI that does not use ML would be chat based robots that operate based on a set of rules. Chat Based robots can operate on a rule-based decision tree, where based on the persons response or option choice, the Chat Bot will then respond with an already pre-determined response that leads to the next stage of the process. An example of ML techniques that do not use Neural Networks are things such as nearest neighbor. This is simple algorithm that stores the data input that is available from all the cases and classifies new data based on how similar it is the previous classified data. Then we get to Deep Learning which uses specifically Neural Networks, which I will go into detail on how this works later on. The specific type of neural network we will use in this project is call a convolutional neural network (CNN). In short you can think of Deep Learning as “Neural-Network Architecture”.
What are the main applications of Deep Learning?
The main applications of Deep Learning are in Image Processing and Language Processing as these are the areas that it performs best.
What are Real World Applications Examples?
Real world applications of Deep Learning are in examples like this project to detect human emotion based on facial recognition. In autonomous cars to process the data taken from the surrounding environment to make sense of it and come to a probable outcome. In computer vision to detect and segment objects. In Snap Chat filters to detect and define the face.
When to use it and not use DL?
The advantages of DL are that it has the best performance on most problems that are applied to ML, it reduces the need for feature engineering, eliminated unnecessary costs, and identifies defects easily that are usually hard to detect. The disadvantages of DL are that it requires a vast amount of data to work properly since we start with little prior knowledge on the subject, computationally expensive to train a network, and there is no strong theoretical background for the field.
What differentiates the ML and DL?
Traditional ML:
- Manually decide on a set of features to implement feature extraction,
- Select a model building method (e.g. SVM) to learn a model
Deep Learning:
- Use neural networks to automate the feature extraction,
- Use neural networks for model building
Overall, the main difference between ML and DL is that you decide upon the set of features and extract manually in ML and in DL all this is done by the model itself.
What is the general concept of a Neural Network?
In essence, what a neural network (NN) does is convert a higher dimensional vector into a lower dimensional vector. The higher dimensional vectors are vectorized representations of the input data and the lower dimensional vector in the output vector. It really just converts an input X into output Y. Here is a visual representation of this:
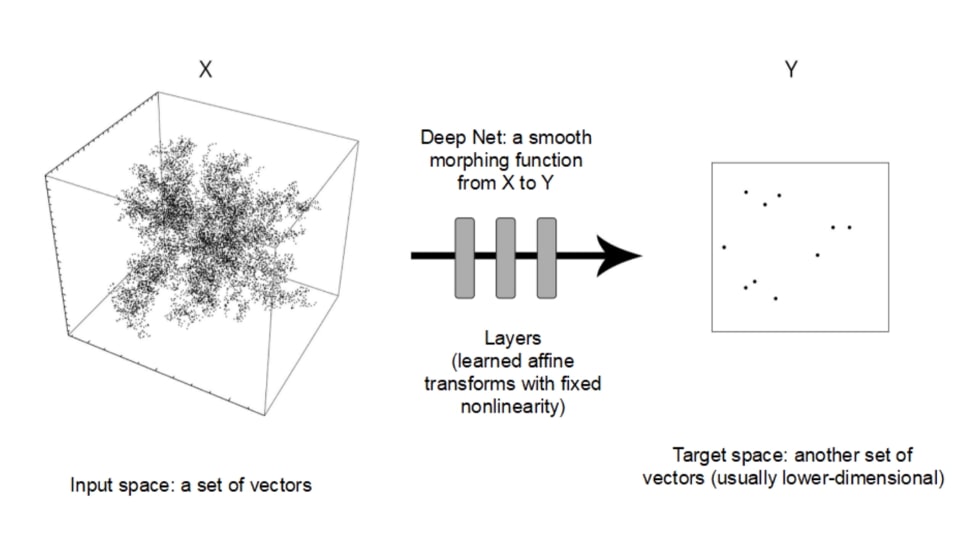
The structure and name of NN were inspired by the human brain and how it in itself learns and thinks, mimicking the way that neurons fire and communicate with one another. Artificial NN are comprised of node layers, containing an input layer, some hidden layers and an output layer. Each node in this layer can be thought of as an artificial neuron. Each node connects to another and has an associated weight and threshold to it. If the input to any given node is above this assigned threshold then it will activate and send data to the next layer. If the node is not activated, then it will not send data to the next layer.
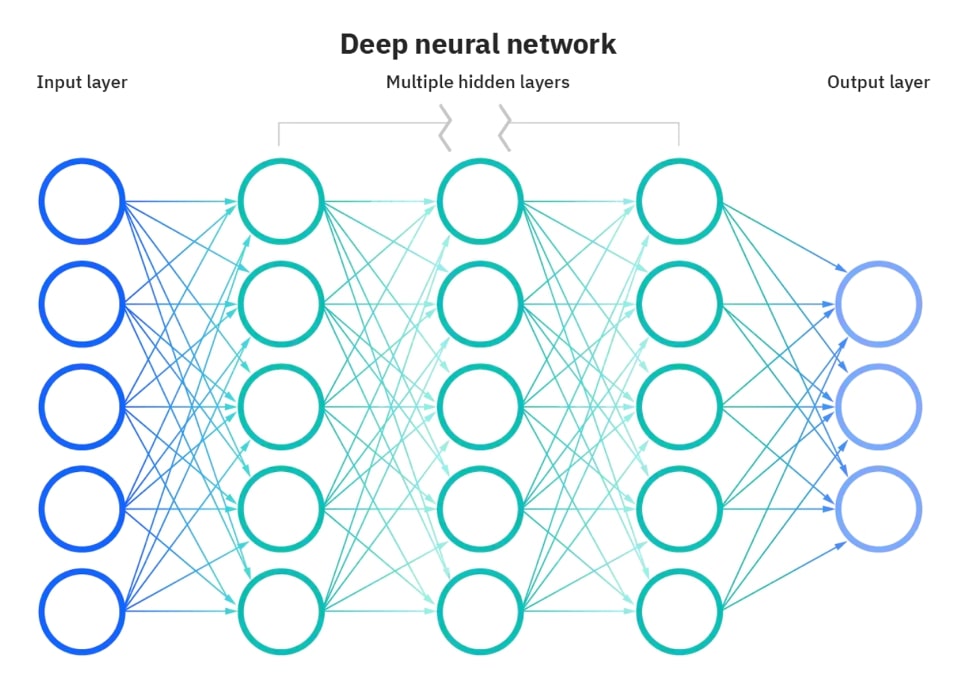
These neural networks are trained on a vast amount of training data, which allows them to improve their accuracy over time. Once a certain NN has been trained, it is a powerful tool and can reduce certain tasks from taking hours to taking minutes.
How do these NN’s work?
The general structure of a NN was described in the previous section. This section will go more in depth into the math and models of how the NN works. You can think of each node in the nodal layer as its own linear regression model, comprised of the input data, weights, bias (threshold), and output. The mathematical model ids shown below:
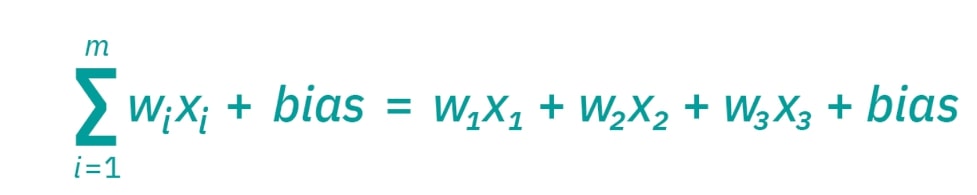
The output based on this nodal equation above, the output is either 1 is the total from this is equal to or above 0 and 0 if it is below 0. The whole process looks likes this:
- Once a layer has been determined, weights are assigned to this layer
- Weights are then multiplied by the input and summed, with larger ones contributing more to the output
- The output is then passed through an activation function which determines if the node fires to the next layer
An example of an activation function is the ReLu function which is commonly used in this project.
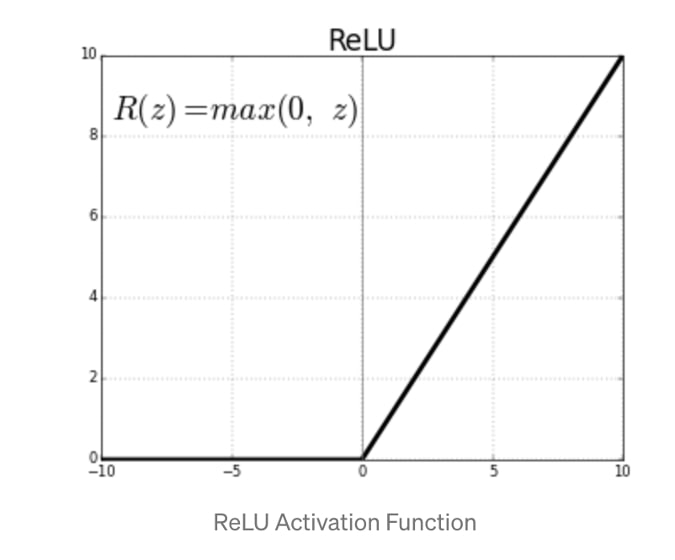
As can be visualized in the above graph and described before, this activation function allows the neuron to fire if the output of the linear regression equation in equal to or above 0 and doesn’t fire if below 0.
Now when training a NN, we want to see its accuracy using a cost (or loss) function. The cost function is made up of the predicted outcome minus the actual outcome for each sample, all summed and divided by the total number of samples. The equation for this is shown below:
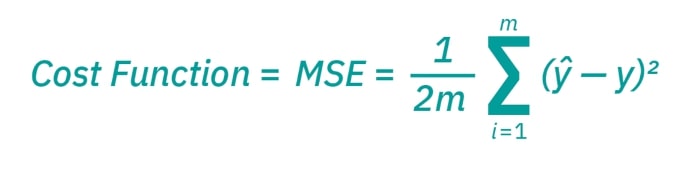
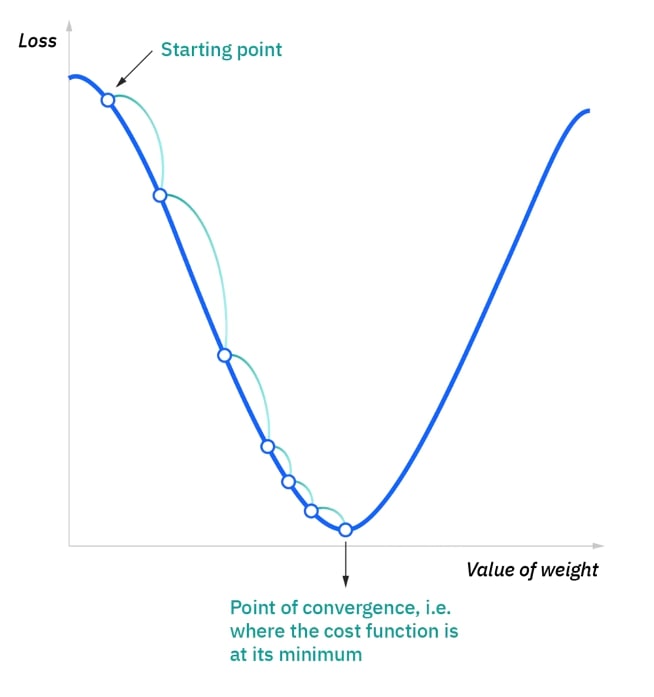
The main goal when training a neural network is minimize this cost function to get the best result for any given observation. The model adjusts its weights and biases to reduce the cost function and reach a local minimum on the cost function. The algorithm for training uses gradient descent to allow it to tell the direction of which the local minimum lies to reduce its errors. The model continues to adjust its weight and biases until this local minimum is hit. An example of this is shown below:
There are many different types of NN, some more complex than others. The specific type that we will use in this project is called Convolutional Neural Networks (CNN) since these are the specific types utilized in image and pattern recognition.
What is a CNN?
In simplified terms, a CNN works by taking an input image, assigning importance to various aspects/objects in that image and being able to differentiate one from the other. The structure of a CNN was inspired by the network of the human Visual Cortex. Individual neurons respond to stimuli found in a restricted region of the image. A collection of these regions overlap to cover the entire image. The reason we use CNN’s over a classic feed forward net was described in the general example above it that they are able to successfully capture the spatial and temporal dependencies in an image. In general, a CNN can be trained to understand the complexities of the image better than a tradition feedforward net where the data is just passed forward and then accessed with a cost function.
You can think of an image as just a matrix of pixel values. Images come in many forms such as Grayscale, RGB, etc. The role of a CNN is to take this complex image and reduce it down into a simpler form while keeping key features.
Recall that a general NN is made up of nodal layers, with each nodes layer containing an input layer, some hidden layers, and an output layer. Knowing this, we can get into specifically how a CNN is constructed in this manner and what are the different layers that go into a CNN nodal layer.
The first layer is the input layer, which takes in the input pixelated image in the format specified when the model was trained. Now that the input pixel image has been taken into the network, it is then passed to a series of hidden High-Level convolutional layers that perform the role of extracting important features from the image and simplifying it. Each of these convolutional layers use convolutional kernels to reduce the dimensionality of the image while keeping key features. This will be covered in depth in a great video at the end of this section. Then the output of the convolutional layer is processed by a batch normalization layer and passed through the activation function. Once the function is activated it is passed to a pooling layer which reduces the spatial size of the convolved feature to decrease the computational power required to process all this data. This process is done many times over until finally passed to the classification layer, output layer. This is the actual feedforward perceptron layer that processed the reduced dimensional image produced form the convolutional layers using the soft-max classification technique, which can be learned about if you want through the additional resources provided at the end of the section.
Watch this helpful video which will make clear everything just discussed in this section and provide a great example to how a CNN works: https://www.youtube.com/watch?v=aircAruvnKk
Overview of MATLAB Deep Learning Toolbox Useful Functions

Different deep learning layers: https://www.mathworks.com/help/deeplearning/ug/list-of-deep-learning-layers.html


Database and Code
%% Load in data, Convert data to Images, and Build Data Base
% Data Source: <https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge>
% Details on Data Source: The data consists of 48x48 pixel grayscale images of faces.
%The faces have been automatically registered so that the face is more or less
%centered and occupies about the same amount of space in each image.
%The task is to categorize each face based on the emotion shown in the facial
%expression in to one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad,
%5=Surprise, 6=Neutral).
% Note this Process of Image Extraction and Database formation form given
% data takes approx 106 seconds
%write file path to check if any images in Angry Emotions
%Folder
filelist = dir(fullfile('/Users/user/Desktop/Emotional Face Recognition Program/database/Angry','*.*'));
if length(filelist) <= 4 %check to see if database already constructed by reading number of files in ANGRY folder
%If the data base is not constructed then run this code
%read in the face data from the data file
datafile = 'icml_face_data.xlsx';
data = readtable(datafile);
%organize the data to put into image pixel arrays from data
%source
dim = size(data); %get size of origional data source
for j = 1:dim(1) %iterate through all facial data component
%read in image file and convert from table to number matrix element
im = data(j,3);
im = table2array(im);
im = cellfun(@str2num,im,'UniformOutput',false);
im = cell2mat(im);
%initialize Image Pixel Array
Image = [];
%Organize image pixel values in data source into image
%48x48 pixel array
for i = 1:48
Image = cat(1,Image,im((((i-1)*48)+1):(i*48)));
end
%need to normalize imgages in order for matlab to be
%able to work with them
maxx = max(Image(:));
minx = min(Image(:));
img = (Image - minx) / (maxx - minx);
%Store Image in data base based ion which emotion it is
databaseFolder = 'database';
emotion = data(j,1); %read emotion label from data base
emotion = table2array(emotion); %convert table element to array
%get correct folder name to store image in
switch(emotion)
case 0
fileFolder = 'Angry';
case 1
fileFolder = 'Disgust';
case 2
fileFolder = 'Fear';
case 3
fileFolder = 'Happy';
case 4
fileFolder = 'Sad';
case 5
fileFolder = 'Suprise';
case 6
fileFolder = 'Neutral';
end
%Store Image Pixel array as a png image in correct database folder
filename = strcat(num2str(j),'.png');%construct file name
filepath = fullfile(databaseFolder,fileFolder,filename); %construct file path to store
imwrite(img,filepath) %store image in correct folder
end
end
Extra Resources
Detailed view of CNN’s: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
More on AI: https://www.ibm.com/cloud/learn/what-is-artificial-intelligence
More on Neural Networks: https://www.ibm.com/cloud/learn/neural-networks
More on Workflow of ML project: https://towardsdatascience.com/workflow-of-a-machine-learning-project-ec1dba419b94
MATLAB Deep Learning Toolbox Documentation: https://www.mathworks.com/help/deeplearning/
DL Applications: https://www.deepinstinct.com/2019/04/16/applications-of-deep-learning/
Overfitting and Underfitting: https://www.geeksforgeeks.org/underfitting-and-overfitting-in-machine-learning/
What is Intelligence: https://www.youtube.com/watch?v=ck4RGeoHFko
What is Consciousness: https://www.youtube.com/watch?v=H6u0VBqNBQ8
What is a CNN: https://www.youtube.com/watch?v=aircAruvnKk
SoftMax Classification Technique: https://towardsdatascience.com/softmax-function-simplified-714068bf8156
CNN lecture (MIT): https://www.youtube.com/watch?v=iaSUYvmCekI
